Przedział ufności
Co to jest przedział ufności:
Jest to oszacowanie zakresu używanego w statystykach, który zawiera parametr populacji. Ten nieznany parametr populacji można znaleźć za pomocą przykładowego modelu obliczonego na podstawie zebranych danych .
Przykład: średnia próbki pobranej x̅ może lub nie może odpowiadać prawdziwej średniej populacji μ. W tym celu możliwe jest rozważenie zakresu średnich próbek, w których ta średnia populacji może być zawarta. Im dłuższy jest ten przedział, tym większe prawdopodobieństwo wystąpienia tego zjawiska.
Przedział ufności jest wyrażony w procentach, wyrażony przez poziom ufności, przy czym najbardziej wskazane jest 90%, 95% i 99%. Na obrazku poniżej, na przykład, mamy 90% przedział ufności między jego górną i dolną granicą (a i -a ).
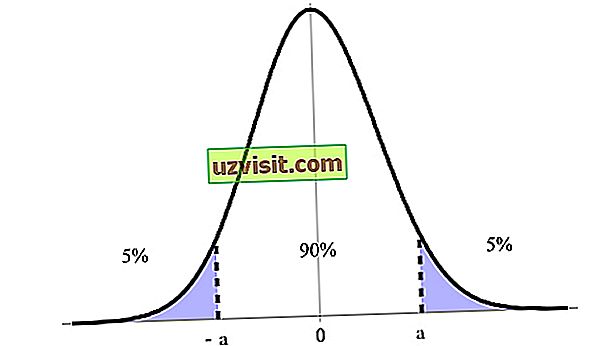
Przedział ufności jest jednym z najważniejszych pojęć w testowaniu hipotez w statystykach, ponieważ jest używany jako miara niepewności. Termin ten wprowadził polski matematyk i statystyk Jerzy Neyman w 1937 roku.
Jakie jest znaczenie przedziału ufności?
Przedział ufności jest ważny dla wskazania marginesu niepewności (lub niedokładności) w stosunku do dokonanego obliczenia. To obliczenie wykorzystuje próbkę badawczą do oszacowania rzeczywistej wielkości wyniku w populacji źródłowej.
Obliczenie przedziału ufności jest strategią uwzględniającą próbkowanie błędów. Wielkość wyniku badania i przedział ufności charakteryzują przypuszczalne wartości dla pierwotnej populacji.
Im węższy przedział ufności, tym większe prawdopodobieństwo, że odsetek badanej populacji reprezentuje rzeczywistą liczbę populacji źródłowej, dając większą pewność co do wyniku obiektu badania.
Jak interpretować przedział ufności?
Prawidłowa interpretacja przedziału ufności jest prawdopodobnie najtrudniejszym aspektem tej koncepcji statystycznej. Przykładem najbardziej powszechnej interpretacji tego pojęcia jest:
Istnieje 95% prawdopodobieństwo, że w przyszłości prawdziwa wartość parametru populacji (np. Średnia) mieści się w zakresie X (dolna granica) i Y (górna granica).
Zatem przedział ufności jest interpretowany w następujący sposób: jest 95% pewny, że przedział między X (dolna granica) i Y (górna granica) zawiera prawdziwą wartość parametru populacji.
Całkowicie błędne byłoby stwierdzenie, że: istnieje 95% prawdopodobieństwo, że przedział między X (dolna granica) i Y (górna granica) zawiera rzeczywistą wartość parametru populacji.
Powyższe stwierdzenie jest najczęstszym błędnym przekonaniem na temat przedziału ufności. Po obliczeniu zakresu statystycznego może on zawierać tylko parametr populacji lub nie.
Jednak interwały mogą się różnić między próbkami, podczas gdy parametr rzeczywistej populacji jest taki sam niezależnie od próbki.
W związku z tym deklaracja ufności przedziału ufności może być wykonana tylko w przypadku, gdy przedziały ufności są ponownie obliczane dla liczby próbek.
Kroki obliczania przedziału ufności
Zakres obliczany jest według następujących kroków:
- Zbierz przykładowe dane: n ;
- Oblicz średnią próbkę x̅;
- Określ, czy odchylenie standardowe populacji ( σ ) jest znane lub nieznane;
- Jeśli znane jest odchylenie standardowe populacji, można zastosować punkt Z dla odpowiedniego poziomu ufności;
- Jeśli odchylenie standardowe populacji jest nieznane, możemy użyć statystyki t dla odpowiedniego poziomu ufności;
- Tak więc dolne i górne granice przedziału ufności znajdują się przy użyciu następujących wzorów:
a) Odchylenie standardowe znanej populacji :
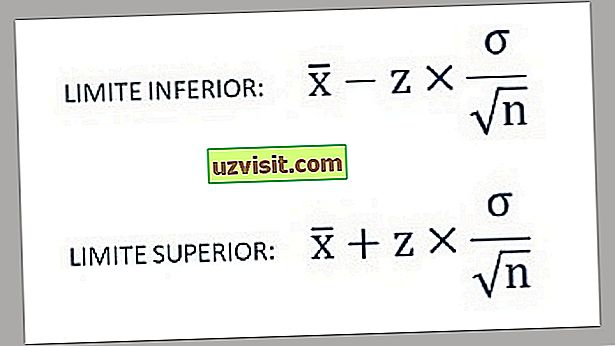
Wzór do obliczania odchylenia standardowego znanej populacji.
b) Odchylenie standardowe nieznanej populacji :

Wzór do obliczania odchylenia standardowego nieznanej populacji.
Praktyczny przykład przedziału ufności
W badaniu klinicznym oceniono związek między występowaniem astmy a ryzykiem rozwoju obturacyjnego bezdechu sennego u dorosłych.
Niektórzy dorośli byli losowo rekrutowani z listy urzędników państwowych, którzy mieli być obserwowani przez cztery lata.
Uczestnicy z astmą, w porównaniu do osób bez, mieli większe ryzyko rozwoju bezdechu w ciągu czterech lat.
Prowadząc badania kliniczne, takie jak ten przykład, podzbiór populacji jest zazwyczaj rekrutowany w celu zwiększenia wydajności badania (mniejsze koszty i mniej czasu).
Ta podgrupa osób, badana populacja, składa się z tych, którzy spełniają kryteria włączenia i zgadzają się uczestniczyć w badaniu, jak pokazano na obrazku poniżej.

Następnie badanie jest zakończone i obliczana jest wielkość efektu (na przykład średnia różnica lub ryzyko względne ), aby odpowiedzieć na pytanie badawcze.
Proces ten, zwany wnioskowaniem, polega na wykorzystaniu danych zebranych z populacji badanej do oszacowania wielkości rzeczywistego wpływu na populację będącą przedmiotem zainteresowania, to znaczy populacji pochodzenia.
W podanym przykładzie naukowcy zwerbowali losową próbkę pracowników państwowych (populacja źródłowa), którzy kwalifikowali się i zgodzili się wziąć udział w badaniu (populacja badana) i zgłosili, że astma zwiększa ryzyko rozwoju bezdechu w badanej populacji.
Aby wyjaśnić błąd próbkowania wynikający z rekrutacji tylko podgrupy populacji będącej przedmiotem zainteresowania, obliczyli również 95% przedział ufności (wokół oszacowania) 1, 06 - 1, 82, wskazując prawdopodobieństwo 95 %, że rzeczywiste ryzyko względne w populacji źródłowej wynosi od 1, 06 do 1, 82 .
Przedział ufności dla średniej
Gdy mamy informacje o odchyleniu standardowym populacji, można obliczyć przedział ufności dla średniej lub średniej tej populacji.
Gdy charakterystyka statystyczna, która jest mierzona (np. Dochód, IQ, cena, wysokość, ilość lub waga) jest liczbowa, w większości przypadków szacuje się, że średnia wartość dla populacji została znaleziona.
Dlatego staramy się znaleźć średnią populacji ( μ ) za pomocą średniej próby ( x̅ ), z marginesem błędu. Wynik tego obliczenia nazywa się przedziałem ufności dla średniej populacji .
Gdy znane jest odchylenie standardowe populacji, wzór na przedział ufności (CI) dla średniej populacji to:

Gdzie:
- x̅ jest średnią próbki;
- σ to standardowe odchylenie populacji;
- n to wielkość próby;
- Ζ * oznacza odpowiednią wartość standardowego rozkładu normalnego dla pożądanego poziomu ufności.
Poniżej podano wartości dla różnych poziomów ufności ( Ζ * ):
| Poziom zaufania | Wartość Z * - |
|---|---|
| 80% | 1.28 |
| 90% | 1.645 (konwencjonalne) |
| 95% | 1, 96 |
| 98% | 2, 33 |
| 99% | 2, 58 |
Powyższa tabela pokazuje wartości z * dla podanych poziomów ufności. Zauważ, że te wartości są uzyskiwane ze standardowego rozkładu normalnego (Z-).
Obszar między każdą wartością z * i ujemną wartością to (przybliżony) procent ufności. Na przykład, obszar między z * = 1, 28 a z = -1, 28 wynosi około 0, 80. W związku z tym ta tabela może być również rozszerzona na inne wartości procentowe ufności. Tabela pokazuje tylko najczęściej używane procenty zaufania.
Zobacz także znaczenie hipotezy.


